| schema location: | C:\Users\chris\Desktop\DataStandards\Audiogram\Fomat 500\Audiogram-1-500.xsd |
| attributeFormDefault: | unqualified |
| elementFormDefault: | qualified |
| targetNamespace: | http://www.himsa.com/Measurement/Audiogram |
element AudMeasurementConditions
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | AudioMetricMeasurementConditions_Type | ||
| properties |
|
||
| children | StimulusSignalType MaskingSignalType StimulusSignalOutput MaskingSignalOutput StimulusdBWeighting MaskingdBWeighting StimulusPresentationType MaskingPresentationType StimulusTransducerType MaskingTransducerType TransducerDescription StimulusTransducerCalibrationStandard MaskingTransducerCalibrationStandard HearingInstrument_1_Condition HearingInstrument_2_Condition HearingInstrumentDescription StimulusAuxiliary MaskingAuxiliary WordListName AuxiliaryParameterDescription SpeechThresholdType StimulusOnTime MaskingOnTime StimulusOffTime MaskingOffTime StimulusSiSiParameter MaskingSiSiParameter StimulusWarbleModulation MaskingWarbleModulation StimulusWarbleModulationSize MaskingWarbleModulationSize StimulusFrequencyModulation MaskingFrequencyModulation StimulusAmplitudeModulation MaskingAmplitudeModulation StimulusPulseModulation MaskingPulseModulation StimulusPulseCycle MaskingPulseCycle | ||
| used by | |||
| annotation |
|
||
| source | <xs:element name="AudMeasurementConditions" type="AudioMetricMeasurementConditions_Type"> <xs:annotation> <xs:documentation>Global Element used throughout this standard - see AudioMetricMeasurementConditions_Type for more details The same set of measurement conditions are used for all Audiogram curves. The Audiogram measurement conditions are very versatile and expandable in such a way that whenever new measurement methods are discovered they can be added to the existing ones. They are meant to be used both by the ENT (Ear, Nose, Throat) for diagnostics purposes and for fitting hearing instruments as well. It is very important to realize that combinations of measurement conditions that make perfect sense to the ENT can be meaningless when programming hearing instruments. It is therefore important to examine all measurement conditions to ascertain whether they are useful for the intended purpose. The measurement conditions have initial (default) values that must be filled in. The following elements are mandatory and have initial values set: StimulusSignalType, MaskingSignalType StimulusSignalOutput, MaskingSignalOutput StimulusdBWeighting, MaskingdBWeighting In addition to the initial default values listed above recording the following audiogram test requires the following elements be set (even though they are listed as optional in the XSD schema file) For tone audiograms these are: StimulusPresentationType, MaskingPresentationType For speech audiograms these are: StimulusAuxiliary MaskingAuxiliary ## TMeasCond ##</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard
| diagram |  |
||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||
| children | ToneThresholdAudiogram UncomfortableLevel MostComfortableLevel SpeechDiscriminationAudiogram SpeechReceptionThresholdAudiogram SpeechMostComfortableLevel SpeechUncomfortableLevel ToneNotes SpeechNotes FrequenciesUsedForToneAverage DecayAudiogram AlternateBinauralLoudnessBalanceAudiogram StengerAudiogram DifferenceLimenIntensity DifferenceLimenFrequency ShortIncrementSensitivityIndex PrivateAudiogramData | ||||||||||||||||||||||||||||||
| attributes |
|
||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||
| source | <xs:element name="HIMSAAudiometricStandard"> <xs:annotation> <xs:documentation>ROOT ELEMENT Important: All XML data must be encoded using UTF-8. With Noah 4.13 and newer Noah validation rules will only allow UTF-8. Including a Byte Order Mark (BOM)is not necessary but considered acceptable Declaring and making use of additional XML Namespaces is not allowed. Noah validation rules will reject the data if detected. REV 6 (see REV History below) HIMSA highly recommends the below 3rd party documentation for individuals not familiar with Audiology. The book is reference throughout this data standard: [HOCA-5] Handbook of Clinical Audiology, edited by Jack Katz, Williams and Wilkins, 2002, 5. Edition For software saving an Audiogram using this data standard: In order not to waste space in the NOAH database it is not legal to save empty elements. For example, do not store <Element/>. Copyright © 2012 HIMSA II K/S The information in this document is subject to change according to the review policies established by HIMSA II. HIMSA II MAKES NO WARRANTY OF ANY KIND WITH REGARD TO THIS MATERIAL, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTY OR SUITABILITY FOR A PARTICULAR PURPOSE. HIMSA shall not be liable for errors contained herein or for incidental consequential damages in connection with the supply of, performance of, or use of this material. This document contains proprietary information that is protected by copyright. All rights are reserved. No parts of this document may be photocopied, reproduced or distributed to Non-HIMSA member companies. without the prior permission of HIMSA II. Copyright © 2012 HIMSA II K/S REV History Final Release / August 15 2011 REV 1 / July 10 2012, Typo and annotation fixes REV 2 / April 30th 2014. - Annotation updates only +++PointStatus_Type annotations were incomplete. Made sure that all annotations in format 200 documentation were included +++SpeechReceptionThresholdAudiogram annotations improved to make it more clear that this element is also used to store SDT and SAT tests. Previously the annotation implied it was only for SRT. REV 3 / August 9 2015 - Annotation updates only. See new annotations for attributes ValidatedByNOAH and ConvertedFromDataStandard REV 4 / January 17 2018 - Annotation updates only. Text "If masking is to be recorded it is then necessary to save values for both MaskingFrequency and MaskingLevel. The XSD was not able to be setup to enforce this rule due to legacy (format 200) design." added to MaskingFrequency and MaskingLevel. This rule already seems to be followed by most companies and the original format 200 documentation stipulates to enter the value if masking is performed. REV 5 / November 1, 2019 - Annotation updates only, note to use UTF-8 REV 6 / December 7 2020 -Annotation updates only, note on UTF-8 and validation, BOM and use of additional namespaces ## Text between these symbols represent type names from the Audiogram standard format 100 and 200 defined via a C header file. During the creation of this schema file HIMSA elected to rename element names to be more human readable. The original type names are listed her for individuals familiar with these names ## @@ Text entered between these symbols denotes special instructions that have been followed if data has been converted up from format 100 or 200. In general, HIMSA has tried to make a 1 to 1 mapping of older formats but in some cases some special rules have been put into place. @@</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element name="ToneThresholdAudiogram" minOccurs="0" maxOccurs="18"> <xs:annotation> <xs:documentation>Standard Tone Hearing Threshold (THR) Audiogram. This is the basic audiogram for recording the patient’s Hearing Threshold Level (HTL). Method: Presentation of Pure tone stimulus via transducer. Masking in the opposite ear is frequently used. Threshold is defined as the 50% response level (softest level at which patient responds to tone 50% of the time). Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation ] ## TToneTHRAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"> <xs:annotation> <xs:documentation> Global Element used throughout this standard - see AudioMetricMeasurementConditions_Type for more details The same set of measurement conditions are used for all Audiogram curves. The Audiogram measurement conditions are very versatile and expandable in such a way that whenever new measurement methods are discovered they can be added to the existing ones. They are meant to be used both by the ENT (Ear, Nose, Throat) for diagnostics purposes and for fitting hearing instruments as well. It is very important to realize that combinations of measurement conditions that make perfect sense to the ENT can be meaningless when programming hearing instruments. It is therefore important to examine all measurement conditions to ascertain whether they are useful for the intended purpose. ## TMeasCond ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="UncomfortableLevel" minOccurs="0" maxOccurs="6"> <xs:annotation> <xs:documentation>Uncomfortable Level Audiogram The lowest signal level, in each ear, which is judged to be uncomfortably loud by the patient. The measurement is usually done with pure tones at audiometric frequencies but may be performed using speech-weighted noise; the signal level has to be expressed relative to a reference value, e.g. as hearing level. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation] ## TToneUCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="MostComfortableLevel" minOccurs="0" maxOccurs="6"> <xs:annotation> <xs:documentation>Most Comfortable Level (MCL) Audiogram This is an area within the residual hearing in which sounds are perceived as comfortable by the patient. Tones presented during this test are pure tones and the patient is asked to respond when they find the sound comfortable. Generally audiologists now try to test to find this area of hearing by concentrating on finding the upper and lower levels of comfort. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation] ## TToneMCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="SpeechDiscriminationAudiogram" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech Discrimination is tested by having the speaker present a one syllable word, usually with a lead in sentence such as ’say the word..’ in lists of 25 or 50, which the listener repeats. These lists are standardized and weighted using all of the speech sounds heard in the chosen language. The percentage of words the listener repeats correctly is the discrimination score. The percentage correct is influenced by the type and degree of hearing loss present. This audiogram plots the results of this test against hearing level Ref. [HOCA-5, Chapter 5, page 71: Speech Audiometry] Note for individuals familiar with earlier versions of this data standard: In previous versions of this standard this Audiogram was documented as a discrimination loss audiogram. The documentation implied that the score would represent the loss not the score. However, this description was in conflict with the definition of the percent score. To correct this documentation error HIMSA has changed the name and description. ## TSpeechDLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechDiscriminationPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="SpeechReceptionThresholdAudiogram" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Stucture for SRT, SDT, and SAT tests SRT - Speech Reception Threshold Audiogram The SRT is also defined as the Threshold of Intelligibility (TI). It is defined as the presentation level (in dB HL) necessary for the patient to reach a score of 50 % when presented for a series of easily understandable phonemes. The SRT can be compared with the tone audiometry thresholds at the frequencies [500, 100, 2000] Hz. The SRT measurement can be carried out as a validation of the Tone Threshold Audiogram. SDT - Speech Detection threshold test / A single word is presented repeatedly and the intensity is increased in 5dB steps and decreased in 10dB steps (like pure tone audiometry) until the point where the patient indicates they can detect, but not repeat the speech heard. Threshold (again like pure tone audiometry) is taken as the level where the patient responds 2 out of 3 or 2 out of 4 times. SAT - Speech Awareness Threshold Test / Same Description as of SDT Set SpeechThreshold_Type to indicate the type of test Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] Ref. [HOCA-5, Chapter 32, page 584: Pseudohypacusis] ## TSpeechSRTAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechReceptionPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="SpeechMostComfortableLevel" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech Most Comfortable Level (MCL) Audiogram. Measurement of Discrimination Loss is done at Most Comfortable Loudness for the patient, normally 30-40 dB above the Speech Reception Threshold (SRT). Some patients might find this level too high (recruitment present). This may make it difficult to find the correct level for recording the MCL speech audiogram. In such cases a complete speech audiogram curve should be recorded. NOTE: only the very MCL point of the speech audiogram can be saved. Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] ## TSpeechMCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechMostComfortablePoint" type="SpeechScorePoint_Type"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="SpeechUncomfortableLevel" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech UnComfortable Level (UCL) Audiogram. The SRT, MCL and UCL for speech audiograms are saved as a single intensity value. A complete speech audiogram curve would show the whole range from Speech Reception Threshold (SRT), to Most Comfortable Level (MCL) to Uncomfortable Level (UCL) Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] ## TSpeechUCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechUncomfortablePoint" type="SpeechScorePoint_Type"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="ToneNotes" type="MeasurementNotes_Type" minOccurs="0"> <xs:annotation> <xs:documentation>Notes added to the Tone Audiogram</xs:documentation> </xs:annotation> </xs:element> <xs:element name="SpeechNotes" type="MeasurementNotes_Type" minOccurs="0"> <xs:annotation> <xs:documentation>Notes added to the Speech Audiogram</xs:documentation> </xs:annotation> </xs:element> <xs:element name="FrequenciesUsedForToneAverage" type="FrequenciesUsedForToneAverage_Type" minOccurs="0"> <xs:annotation> <xs:documentation>This structure allows specification of certain frequencies at which the pure tone average should be calculated. Each ear has two average values to allow for “double-weighting” of certain values as required in certain countries like Japan. The average calculation method is applied to all averages for the given ear, so there is no opportunity to specify a different pure tone average calculation method for bone conduction than is used for air conduction, etc. The rationale behind only a single set of information for each of left and right ears is that it really does not make sense to calculate the average differently between two different tests. A note on the double weighting: Essentially, if the set specifies to weight averages at 500,1000,1500 Hz and the second specifies 1000 Hz, then the average would be calculated as follows: (ValueAt(500) + (2 * ValueAt(1000)) + ValueAt(1500)) / 4 If the ValueAt(1000) for the left ear is maybe unreliable, a better average is sought for that ear but you can still leave the right ear calculation unchanged. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation ] ## TToneAvgCalcValues ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="DecayAudiogram" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Testing involves the presentation of a sustained pure tone at or above the patient’s hearing threshold. The patient indicates when the tone is heard and when it disappears. The tone is presented at increasing levels until it is continuously heard for a set amount of time. Tone decay is defined as a reduction in the ability to hear a sustained tone, and is indicative of a retrocochlear hearing loss. Tone decay can be carried out at any frequency, and methods including the presentation levels vary in the research literature. Ref. [HOCA-5, Chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] ## TDecayAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="DecayPoints" type="DecayPoint_Type" maxOccurs="50"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="AlternateBinauralLoudnessBalanceAudiogram" minOccurs="0"> <xs:annotation> <xs:documentation>A sound of constant intensity is presented to the patient’s good ear for a few seconds. A sound is then presented to the patient’s bad ear. The patient is asked to judge if the sounds are of equal loudness. The sound in the bad ear is varied until a loudness match with the good ear is found. The level of the tone presented to the good ear is then increased and the procedure repeated. At each frequency tested a graph is produced where equal loudness judgments are connected with a straight line. Abnormal growth of loudness is an indication of cochlear hearing loss and is termed recruitment. Ref. [HOCA-5, Chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] ## TABLBAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="AlternateBinauralLoudnessBalancePoints" type="TonePoints_Type" maxOccurs="192"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="StengerAudiogram" minOccurs="0"> <xs:annotation> <xs:documentation>The Stenger test is used when a patient claims that his hearing is impaired in one ear but the Audiologists does not believe them. This test can only be performed if the difference in thresholds between ears is ≥ 20 dB. It involves presentation of a tone of one frequency to both ears and is based on the principle that when 2 tones of the same frequency are introduced simultaneously to both ears, only the louder tone will be perceived. The audiometer should allow separate intensity control for each channel. The tone is first introduced to the good ear at a level which is 5-10 dB above the known threshold. The same frequency tone is then simultaneously presented to the “bad” ear at a level 10 dB below the (admitted) threshold. If the patient is simulating a hearing loss he would hear the tone louder in the bad ear, and would, therefore, not respond to the tone, since he/she does not want to admit to hearing in the bad ear and is unaware of the tone in the good ear. If the patient has a loss in the bad ear as measured, he/she will respond to the tone in the good ear. If the patient was found to be dishonest then a new audiogram would be saved. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5 chapter 32, page 584: Pseudohypacusis] ## TSTStengerAudiogram#</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="StengerPoints" type="TonePoints_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="DifferenceLimenIntensity" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Difference Limen Intensity Audiogram also called Amplitude Modulation (AM) Test or the Lüscher-Zwislocki test. In this audiogram, an Amplitude Modulation is added to a steady tone, and the patient is asked to indicate the smallest variation he can detect. The result is then recorded in dB. The most significant level of recording is found to be approx. 40 dB above the hearing threshold. Ref. [HOCA-5 chapter 3, page 33: Pseudohypacusis] ## TDLIAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="DifferenceLimenIntensityPoints" type="DifferenceLimenIntensityPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLIPoint ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="DifferenceLimenFrequency" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Difference Limen Frequency Audiogram also called Frequency Modulation (FM) Test. In this audiogram, a Frequency Modulation is added to a steady tone, and the patient is asked to indicate the smallest variation he can detect. This test is used to diagnose abnormal growth of loudness in cochlear hearing losses. The result is then recorded in percentage. Ref. [HOCA-5 chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] Ref. [HOCA-5 chapter 3, page 33: Pseudohypacusis] ## TDLFAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"> <xs:annotation> <xs:documentation> Global Element used throughout this standard - see AudioMetricMeasurementConditions_Type for more details ## TMeasCond ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="DifferenceLimenFrequencyPoints" type="DifferenceLimenFrequencyPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLFPoint ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="ShortIncrementSensitivityIndex" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Short increment sensitivity index testing is where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. The patient signals if the rise is heard. 20 rises are presented and the score then multiplied by 5 to give a percentage score. People with cochlear losses are likely to score above 70% where as normal hearing and other losses typically score less than 30% Ref. [HOCA-5 chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests] ## TSISIAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="ShortIncrementSensitivityIndexPoints" type="ShortIncrementSensitivityIndexPoint" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> <xs:element name="PrivateAudiogramData" type="xs:base64Binary" minOccurs="0"> <xs:annotation> <xs:documentation>In the past it was allowed by HIMSA to save privately formatted data in the unused section of the public storage area of a NOAH action. This usage was used mainly because more space was allocated for public storage versus private. At present this is no longer an issue as equal storage is allocated to both public and private data storage. This elements primary function is to pass along any private data stored in the public area as base64 encoded data. NOAH is not performing any translation or conversion of data. This data will never be converted back to an earlier version of a Audiogram data standard. For example, if an audiogram format 500 is saved with this element populated and then an older NOAH compatible fitting module tries to read the Audiogram (causing a conversion down to format 200) this data will be ignored by the converter process. </xs:documentation> </xs:annotation> </xs:element> </xs:sequence> <xs:attribute name="Version" use="required" fixed="500"> <xs:annotation> <xs:documentation>Version of this data standard </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:integer"> <xs:minInclusive value="500"/> </xs:restriction> </xs:simpleType> </xs:attribute> <xs:attribute name="ValidatedByNOAH" type="xs:boolean" use="optional"> <xs:annotation> <xs:documentation>This attribute is no longer in use. The original intention was for Noah to fill in the value but the idea was never fully implemented and not needed.</xs:documentation> </xs:annotation> </xs:attribute> <xs:attribute name="ConvertedFromDataStandard"> <xs:annotation> <xs:documentation>Software saving data formatted via this XSD file should not use this element for storage. The intention is for Noah data convertors to fill in an appropriate value for runtime conversions - not permanent storage. Please note that values less than 500 mean that the data was originally stored in a format which was not validated by Noah before storage. This could mean that the data will not validated against this version</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:integer"> <xs:minInclusive value="100"/> </xs:restriction> </xs:simpleType> </xs:attribute> </xs:complexType> </xs:element> |
attribute HIMSAAudiometricStandard/@Version
| type | restriction of xs:integer | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:attribute name="Version" use="required" fixed="500"> <xs:annotation> <xs:documentation>Version of this data standard </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:integer"> <xs:minInclusive value="500"/> </xs:restriction> </xs:simpleType> </xs:attribute> |
attribute HIMSAAudiometricStandard/@ValidatedByNOAH
| type | xs:boolean | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:attribute name="ValidatedByNOAH" type="xs:boolean" use="optional"> <xs:annotation> <xs:documentation>This attribute is no longer in use. The original intention was for Noah to fill in the value but the idea was never fully implemented and not needed.</xs:documentation> </xs:annotation> </xs:attribute> |
attribute HIMSAAudiometricStandard/@ConvertedFromDataStandard
| type | restriction of xs:integer | ||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:attribute name="ConvertedFromDataStandard"> <xs:annotation> <xs:documentation>Software saving data formatted via this XSD file should not use this element for storage. The intention is for Noah data convertors to fill in an appropriate value for runtime conversions - not permanent storage. Please note that values less than 500 mean that the data was originally stored in a format which was not validated by Noah before storage. This could mean that the data will not validated against this version</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:integer"> <xs:minInclusive value="100"/> </xs:restriction> </xs:simpleType> </xs:attribute> |
element HIMSAAudiometricStandard/ToneThresholdAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions TonePoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="ToneThresholdAudiogram" minOccurs="0" maxOccurs="18"> <xs:annotation> <xs:documentation>Standard Tone Hearing Threshold (THR) Audiogram. This is the basic audiogram for recording the patient’s Hearing Threshold Level (HTL). Method: Presentation of Pure tone stimulus via transducer. Masking in the opposite ear is frequently used. Threshold is defined as the 50% response level (softest level at which patient responds to tone 50% of the time). Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation ] ## TToneTHRAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"> <xs:annotation> <xs:documentation> Global Element used throughout this standard - see AudioMetricMeasurementConditions_Type for more details The same set of measurement conditions are used for all Audiogram curves. The Audiogram measurement conditions are very versatile and expandable in such a way that whenever new measurement methods are discovered they can be added to the existing ones. They are meant to be used both by the ENT (Ear, Nose, Throat) for diagnostics purposes and for fitting hearing instruments as well. It is very important to realize that combinations of measurement conditions that make perfect sense to the ENT can be meaningless when programming hearing instruments. It is therefore important to examine all measurement conditions to ascertain whether they are useful for the intended purpose. ## TMeasCond ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/ToneThresholdAudiogram/TonePoints
| diagram | 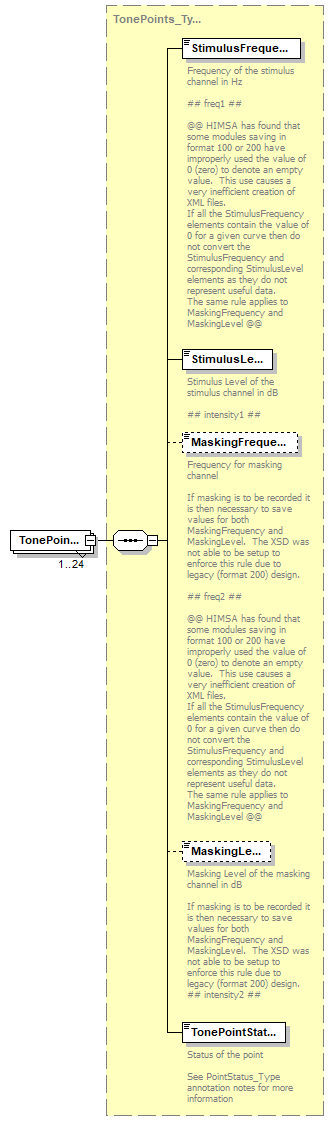 |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | TonePoints_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||||||
| source | <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> |
element HIMSAAudiometricStandard/UncomfortableLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions TonePoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="UncomfortableLevel" minOccurs="0" maxOccurs="6"> <xs:annotation> <xs:documentation>Uncomfortable Level Audiogram The lowest signal level, in each ear, which is judged to be uncomfortably loud by the patient. The measurement is usually done with pure tones at audiometric frequencies but may be performed using speech-weighted noise; the signal level has to be expressed relative to a reference value, e.g. as hearing level. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation] ## TToneUCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/UncomfortableLevel/TonePoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | TonePoints_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||||||
| source | <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> |
element HIMSAAudiometricStandard/MostComfortableLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions TonePoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="MostComfortableLevel" minOccurs="0" maxOccurs="6"> <xs:annotation> <xs:documentation>Most Comfortable Level (MCL) Audiogram This is an area within the residual hearing in which sounds are perceived as comfortable by the patient. Tones presented during this test are pure tones and the patient is asked to respond when they find the sound comfortable. Generally audiologists now try to test to find this area of hearing by concentrating on finding the upper and lower levels of comfort. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation] ## TToneMCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/MostComfortableLevel/TonePoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | TonePoints_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||||||
| source | <xs:element name="TonePoints" type="TonePoints_Type" maxOccurs="24"/> |
element HIMSAAudiometricStandard/SpeechDiscriminationAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions SpeechDiscriminationPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="SpeechDiscriminationAudiogram" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech Discrimination is tested by having the speaker present a one syllable word, usually with a lead in sentence such as ’say the word..’ in lists of 25 or 50, which the listener repeats. These lists are standardized and weighted using all of the speech sounds heard in the chosen language. The percentage of words the listener repeats correctly is the discrimination score. The percentage correct is influenced by the type and degree of hearing loss present. This audiogram plots the results of this test against hearing level Ref. [HOCA-5, Chapter 5, page 71: Speech Audiometry] Note for individuals familiar with earlier versions of this data standard: In previous versions of this standard this Audiogram was documented as a discrimination loss audiogram. The documentation implied that the score would represent the loss not the score. However, this description was in conflict with the definition of the percent score. To correct this documentation error HIMSA has changed the name and description. ## TSpeechDLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechDiscriminationPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/SpeechDiscriminationAudiogram/SpeechDiscriminationPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | SpeechScorePoint_Type | ||||||
| properties |
|
||||||
| children | StimulusLevel MaskingLevel ScorePercent NumberOfWords | ||||||
| source | <xs:element name="SpeechDiscriminationPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> |
element HIMSAAudiometricStandard/SpeechReceptionThresholdAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions SpeechReceptionPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="SpeechReceptionThresholdAudiogram" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Stucture for SRT, SDT, and SAT tests SRT - Speech Reception Threshold Audiogram The SRT is also defined as the Threshold of Intelligibility (TI). It is defined as the presentation level (in dB HL) necessary for the patient to reach a score of 50 % when presented for a series of easily understandable phonemes. The SRT can be compared with the tone audiometry thresholds at the frequencies [500, 100, 2000] Hz. The SRT measurement can be carried out as a validation of the Tone Threshold Audiogram. SDT - Speech Detection threshold test / A single word is presented repeatedly and the intensity is increased in 5dB steps and decreased in 10dB steps (like pure tone audiometry) until the point where the patient indicates they can detect, but not repeat the speech heard. Threshold (again like pure tone audiometry) is taken as the level where the patient responds 2 out of 3 or 2 out of 4 times. SAT - Speech Awareness Threshold Test / Same Description as of SDT Set SpeechThreshold_Type to indicate the type of test Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] Ref. [HOCA-5, Chapter 32, page 584: Pseudohypacusis] ## TSpeechSRTAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechReceptionPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/SpeechReceptionThresholdAudiogram/SpeechReceptionPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | SpeechScorePoint_Type | ||||||
| properties |
|
||||||
| children | StimulusLevel MaskingLevel ScorePercent NumberOfWords | ||||||
| source | <xs:element name="SpeechReceptionPoints" type="SpeechScorePoint_Type" maxOccurs="24"/> |
element HIMSAAudiometricStandard/SpeechMostComfortableLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions SpeechMostComfortablePoint | ||||||
| annotation |
|
||||||
| source | <xs:element name="SpeechMostComfortableLevel" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech Most Comfortable Level (MCL) Audiogram. Measurement of Discrimination Loss is done at Most Comfortable Loudness for the patient, normally 30-40 dB above the Speech Reception Threshold (SRT). Some patients might find this level too high (recruitment present). This may make it difficult to find the correct level for recording the MCL speech audiogram. In such cases a complete speech audiogram curve should be recorded. NOTE: only the very MCL point of the speech audiogram can be saved. Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] ## TSpeechMCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechMostComfortablePoint" type="SpeechScorePoint_Type"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/SpeechMostComfortableLevel/SpeechMostComfortablePoint
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | SpeechScorePoint_Type | ||
| properties |
|
||
| children | StimulusLevel MaskingLevel ScorePercent NumberOfWords | ||
| source | <xs:element name="SpeechMostComfortablePoint" type="SpeechScorePoint_Type"/> |
element HIMSAAudiometricStandard/SpeechUncomfortableLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions SpeechUncomfortablePoint | ||||||
| annotation |
|
||||||
| source | <xs:element name="SpeechUncomfortableLevel" minOccurs="0" maxOccurs="12"> <xs:annotation> <xs:documentation>Speech UnComfortable Level (UCL) Audiogram. The SRT, MCL and UCL for speech audiograms are saved as a single intensity value. A complete speech audiogram curve would show the whole range from Speech Reception Threshold (SRT), to Most Comfortable Level (MCL) to Uncomfortable Level (UCL) Ref. [HOCA-5, Chapter 7, page 96: Speech Audiometry] ## TSpeechUCLAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="SpeechUncomfortablePoint" type="SpeechScorePoint_Type"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/SpeechUncomfortableLevel/SpeechUncomfortablePoint
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | SpeechScorePoint_Type | ||
| properties |
|
||
| children | StimulusLevel MaskingLevel ScorePercent NumberOfWords | ||
| source | <xs:element name="SpeechUncomfortablePoint" type="SpeechScorePoint_Type"/> |
element HIMSAAudiometricStandard/ToneNotes
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | MeasurementNotes_Type | ||||||
| properties |
|
||||||
| children | AudiometerMakeModel AudiometerSerialNumber AudiometerLastCalibration TestMethod TestReliability | ||||||
| annotation |
|
||||||
| source | <xs:element name="ToneNotes" type="MeasurementNotes_Type" minOccurs="0"> <xs:annotation> <xs:documentation>Notes added to the Tone Audiogram</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/SpeechNotes
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | MeasurementNotes_Type | ||||||
| properties |
|
||||||
| children | AudiometerMakeModel AudiometerSerialNumber AudiometerLastCalibration TestMethod TestReliability | ||||||
| annotation |
|
||||||
| source | <xs:element name="SpeechNotes" type="MeasurementNotes_Type" minOccurs="0"> <xs:annotation> <xs:documentation>Notes added to the Speech Audiogram</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/FrequenciesUsedForToneAverage
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | FrequenciesUsedForToneAverage_Type | ||||||
| properties |
|
||||||
| children | LeftEar1 LeftEar2 RightEar1 RightEar2 | ||||||
| annotation |
|
||||||
| source | <xs:element name="FrequenciesUsedForToneAverage" type="FrequenciesUsedForToneAverage_Type" minOccurs="0"> <xs:annotation> <xs:documentation>This structure allows specification of certain frequencies at which the pure tone average should be calculated. Each ear has two average values to allow for “double-weighting” of certain values as required in certain countries like Japan. The average calculation method is applied to all averages for the given ear, so there is no opportunity to specify a different pure tone average calculation method for bone conduction than is used for air conduction, etc. The rationale behind only a single set of information for each of left and right ears is that it really does not make sense to calculate the average differently between two different tests. A note on the double weighting: Essentially, if the set specifies to weight averages at 500,1000,1500 Hz and the second specifies 1000 Hz, then the average would be calculated as follows: (ValueAt(500) + (2 * ValueAt(1000)) + ValueAt(1500)) / 4 If the ValueAt(1000) for the left ear is maybe unreliable, a better average is sought for that ear but you can still leave the right ear calculation unchanged. Ref. [HOCA-5, Chapter 5, page 71: Puretone Evaluation ] ## TToneAvgCalcValues ##</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/DecayAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions DecayPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="DecayAudiogram" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Testing involves the presentation of a sustained pure tone at or above the patient’s hearing threshold. The patient indicates when the tone is heard and when it disappears. The tone is presented at increasing levels until it is continuously heard for a set amount of time. Tone decay is defined as a reduction in the ability to hear a sustained tone, and is indicative of a retrocochlear hearing loss. Tone decay can be carried out at any frequency, and methods including the presentation levels vary in the research literature. Ref. [HOCA-5, Chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] ## TDecayAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="DecayPoints" type="DecayPoint_Type" maxOccurs="50"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/DecayAudiogram/DecayPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | DecayPoint_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel StartTime EndTime | ||||||
| source | <xs:element name="DecayPoints" type="DecayPoint_Type" maxOccurs="50"/> |
element HIMSAAudiometricStandard/AlternateBinauralLoudnessBalanceAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions AlternateBinauralLoudnessBalancePoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="AlternateBinauralLoudnessBalanceAudiogram" minOccurs="0"> <xs:annotation> <xs:documentation>A sound of constant intensity is presented to the patient’s good ear for a few seconds. A sound is then presented to the patient’s bad ear. The patient is asked to judge if the sounds are of equal loudness. The sound in the bad ear is varied until a loudness match with the good ear is found. The level of the tone presented to the good ear is then increased and the procedure repeated. At each frequency tested a graph is produced where equal loudness judgments are connected with a straight line. Abnormal growth of loudness is an indication of cochlear hearing loss and is termed recruitment. Ref. [HOCA-5, Chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] ## TABLBAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="AlternateBinauralLoudnessBalancePoints" type="TonePoints_Type" maxOccurs="192"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/AlternateBinauralLoudnessBalanceAudiogram/AlternateBinauralLoudnessBalancePoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | TonePoints_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||||||
| annotation |
|
||||||
| source | <xs:element name="AlternateBinauralLoudnessBalancePoints" type="TonePoints_Type" maxOccurs="192"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/StengerAudiogram
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions StengerPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="StengerAudiogram" minOccurs="0"> <xs:annotation> <xs:documentation>The Stenger test is used when a patient claims that his hearing is impaired in one ear but the Audiologists does not believe them. This test can only be performed if the difference in thresholds between ears is ≥ 20 dB. It involves presentation of a tone of one frequency to both ears and is based on the principle that when 2 tones of the same frequency are introduced simultaneously to both ears, only the louder tone will be perceived. The audiometer should allow separate intensity control for each channel. The tone is first introduced to the good ear at a level which is 5-10 dB above the known threshold. The same frequency tone is then simultaneously presented to the “bad” ear at a level 10 dB below the (admitted) threshold. If the patient is simulating a hearing loss he would hear the tone louder in the bad ear, and would, therefore, not respond to the tone, since he/she does not want to admit to hearing in the bad ear and is unaware of the tone in the good ear. If the patient has a loss in the bad ear as measured, he/she will respond to the tone in the good ear. If the patient was found to be dishonest then a new audiogram would be saved. Note that the max. 24 curve points can come in any order as [frequency, intensity] pairs. Each point is properly identified by its standard frequency for which the intensity is recorded. Ref. [HOCA-5 chapter 32, page 584: Pseudohypacusis] ## TSTStengerAudiogram#</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="StengerPoints" type="TonePoints_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/StengerAudiogram/StengerPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | TonePoints_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||||||
| annotation |
|
||||||
| source | <xs:element name="StengerPoints" type="TonePoints_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>Masking Level and Masking Frequency are used to denote the stimulus in channel 2 of the Audiometer which would always be a pure tone</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/DifferenceLimenIntensity
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions DifferenceLimenIntensityPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="DifferenceLimenIntensity" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Difference Limen Intensity Audiogram also called Amplitude Modulation (AM) Test or the Lüscher-Zwislocki test. In this audiogram, an Amplitude Modulation is added to a steady tone, and the patient is asked to indicate the smallest variation he can detect. The result is then recorded in dB. The most significant level of recording is found to be approx. 40 dB above the hearing threshold. Ref. [HOCA-5 chapter 3, page 33: Pseudohypacusis] ## TDLIAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="DifferenceLimenIntensityPoints" type="DifferenceLimenIntensityPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLIPoint ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/DifferenceLimenIntensity/DifferenceLimenIntensityPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | DifferenceLimenIntensityPoint_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize DifferenceLimenIntensityPointStatus | ||||||
| annotation |
|
||||||
| source | <xs:element name="DifferenceLimenIntensityPoints" type="DifferenceLimenIntensityPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLIPoint ##</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/DifferenceLimenFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions DifferenceLimenFrequencyPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="DifferenceLimenFrequency" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Difference Limen Frequency Audiogram also called Frequency Modulation (FM) Test. In this audiogram, a Frequency Modulation is added to a steady tone, and the patient is asked to indicate the smallest variation he can detect. This test is used to diagnose abnormal growth of loudness in cochlear hearing losses. The result is then recorded in percentage. Ref. [HOCA-5 chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests ] Ref. [HOCA-5 chapter 3, page 33: Pseudohypacusis] ## TDLFAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"> <xs:annotation> <xs:documentation> Global Element used throughout this standard - see AudioMetricMeasurementConditions_Type for more details ## TMeasCond ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="DifferenceLimenFrequencyPoints" type="DifferenceLimenFrequencyPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLFPoint ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/DifferenceLimenFrequency/DifferenceLimenFrequencyPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | DifferenceLimenFrequencyPoint_Type | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize DifferenceLimenFrequencyPointStatus | ||||||
| annotation |
|
||||||
| source | <xs:element name="DifferenceLimenFrequencyPoints" type="DifferenceLimenFrequencyPoint_Type" maxOccurs="24"> <xs:annotation> <xs:documentation>## TDLFPoint ##</xs:documentation> </xs:annotation> </xs:element> |
element HIMSAAudiometricStandard/ShortIncrementSensitivityIndex
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| properties |
|
||||||
| children | AudMeasurementConditions ShortIncrementSensitivityIndexPoints | ||||||
| annotation |
|
||||||
| source | <xs:element name="ShortIncrementSensitivityIndex" minOccurs="0" maxOccurs="2"> <xs:annotation> <xs:documentation>Short increment sensitivity index testing is where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. The patient signals if the rise is heard. 20 rises are presented and the score then multiplied by 5 to give a percentage score. People with cochlear losses are likely to score above 70% where as normal hearing and other losses typically score less than 30% Ref. [HOCA-5 chapter 8, page 111: Cochlear and Retrocochlear Behavioral Tests] ## TSISIAudiogram ##</xs:documentation> </xs:annotation> <xs:complexType> <xs:sequence> <xs:element ref="AudMeasurementConditions"/> <xs:element name="ShortIncrementSensitivityIndexPoints" type="ShortIncrementSensitivityIndexPoint" maxOccurs="24"/> </xs:sequence> </xs:complexType> </xs:element> |
element HIMSAAudiometricStandard/ShortIncrementSensitivityIndex/ShortIncrementSensitivityIndexPoints
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | ShortIncrementSensitivityIndexPoint | ||||||
| properties |
|
||||||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize NumberOfAnswers NumberOfIncrements | ||||||
| source | <xs:element name="ShortIncrementSensitivityIndexPoints" type="ShortIncrementSensitivityIndexPoint" maxOccurs="24"/> |
element HIMSAAudiometricStandard/PrivateAudiogramData
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:base64Binary | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="PrivateAudiogramData" type="xs:base64Binary" minOccurs="0"> <xs:annotation> <xs:documentation>In the past it was allowed by HIMSA to save privately formatted data in the unused section of the public storage area of a NOAH action. This usage was used mainly because more space was allocated for public storage versus private. At present this is no longer an issue as equal storage is allocated to both public and private data storage. This elements primary function is to pass along any private data stored in the public area as base64 encoded data. NOAH is not performing any translation or conversion of data. This data will never be converted back to an earlier version of a Audiogram data standard. For example, if an audiogram format 500 is saved with this element populated and then an older NOAH compatible fitting module tries to read the Audiogram (causing a conversion down to format 200) this data will be ignored by the converter process. </xs:documentation> </xs:annotation> </xs:element> |
complexType AudioMetricMeasurementConditions_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusSignalType MaskingSignalType StimulusSignalOutput MaskingSignalOutput StimulusdBWeighting MaskingdBWeighting StimulusPresentationType MaskingPresentationType StimulusTransducerType MaskingTransducerType TransducerDescription StimulusTransducerCalibrationStandard MaskingTransducerCalibrationStandard HearingInstrument_1_Condition HearingInstrument_2_Condition HearingInstrumentDescription StimulusAuxiliary MaskingAuxiliary WordListName AuxiliaryParameterDescription SpeechThresholdType StimulusOnTime MaskingOnTime StimulusOffTime MaskingOffTime StimulusSiSiParameter MaskingSiSiParameter StimulusWarbleModulation MaskingWarbleModulation StimulusWarbleModulationSize MaskingWarbleModulationSize StimulusFrequencyModulation MaskingFrequencyModulation StimulusAmplitudeModulation MaskingAmplitudeModulation StimulusPulseModulation MaskingPulseModulation StimulusPulseCycle MaskingPulseCycle | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="AudioMetricMeasurementConditions_Type"> <xs:annotation> <xs:documentation>Measuring Conditions for each recorded curve </xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusSignalType" default="NoSignalApplied"> <xs:annotation> <xs:documentation>Stimulus signal is the sound being presented to the patient, in the ear being tested, that you want them to respond to. (e.g. Pure Tone) @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalType1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="Signal_Type"/> </xs:simpleType> </xs:element> <xs:element name="MaskingSignalType" type="Signal_Type" default="NoSignalApplied"> <xs:annotation> <xs:documentation>This is a sound used to stop the hearing in an ear that is not being tested from picking up the test signal. Often used when one ear is found to be significantly poorer than the other or for bone conduction testing. The non test ear picking up the test tone is called crossover. Masking is presented to the non test ear. An example of masking noise commonly used is narrowband noise (NBN) The enumerated value "NoSignalApplied" signals that masking has NOT been performed. If masking has been used then a value other then NoSignalApplied will and must be used. Ref. [HOCA-5, Chapter 9, page 124: Clinical Masking] ## SignalType2 ## @@ Translator/Converter RULE In the Audiogram format 100 and 200 it has been unclearly documented the exact method that must be used to note if masking is used or not. In some cases the signalType2 would be set correctly or in some cases it was not but yet freq2 or intentisty2 would be set (e.g. masking points would be saved). In other words there have been two ways to indicate that masking has been used. If a NOAH compatible program is to create an Audiogram using this XSD file and wishes to state that masking has not been used then it must set “NoSignalApplied” If a NOAH compatible program is reading format 100 or 200 translated to XML then the translator DLL must follow the below rule If (SignalType2 = NoSignal) AND There is at least (1 value for freq2 OR intensity2) for any of the available points then MaskingSignalType = “Unknown” @@</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusSignalOutput" type="SignalOutput_Type" default="NoSignalOutput"> <xs:annotation> <xs:documentation>This refers to the method used to deliver the sound the patient responds to. The ear and way the sound is delivered is specified but not the exact device used to deliver that sound (e.g. left air conduction not TDH39) See annotations for SignalOutput_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalOutput1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingSignalOutput" type="SignalOutput_Type" default="NoSignalOutput"> <xs:annotation> <xs:documentation>This refers to the method used to deliver the masking sound to the patient. The ear and way the sound is delivered is specified but not the exact device used to deliver that sound. (e.g. left air conduction not TDH39) See annotations for SignalOutput_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalOutput2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusdBWeighting" type="dBweighting_Type" default="NodBWeighting"> <xs:annotation> <xs:documentation>The weighting used for the stimulus signal. See annotations for dBweighting_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## dBWeighting1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingdBWeighting" type="dBweighting_Type" default="NodBWeighting"> <xs:annotation> <xs:documentation>The weighting used for the masking signal. See annotations for dBweighting_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## dBWeighting2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusPresentationType" default="NoPresentationType" minOccurs="0"> <xs:annotation> <xs:documentation>Presentation Type for the Stimulus signal See annotations for Presentation_Type for more information ## presentType1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="Presentation_Type"/> </xs:simpleType> </xs:element> <xs:element name="MaskingPresentationType" type="Presentation_Type" default="NoPresentationType" minOccurs="0"> <xs:annotation> <xs:documentation>Presentation Type for the Masking signal See annotations for Presentation_Type for more information ## presentType 2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusTransducerType" type="Transducer_Type" default="NoTransducerType" minOccurs="0"> <xs:annotation> <xs:documentation>The device used to deliver sound to the test ear. See annotations for Transducer_Type for more information ## transType1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingTransducerType" type="Transducer_Type" default="NoTransducerType" minOccurs="0"> <xs:annotation> <xs:documentation>The device used to deliver sound to the non test ear. See annotations for Transducer_Type for more information ## transType2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="TransducerDescription" default="" minOccurs="0"> <xs:annotation> <xs:documentation>Optional description of the Transducer ## transDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusTransducerCalibrationStandard" type="TransducerCalibrationStandard_Type" default="NoTransducerCalibrationStandard" minOccurs="0"> <xs:annotation> <xs:documentation>Standard used for the Stimulus Transducer Calibration See annotations for Transducer_Type for more information Ref. [HOCA-5, Chapter 4, page 50: Puretone, Speech and Noise signals] ## transCalStand1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingTransducerCalibrationStandard" type="TransducerCalibrationStandard_Type" default="NoTransducerCalibrationStandard" minOccurs="0"> <xs:annotation> <xs:documentation>Standard used for the MaskingTransducer Calibration See annotations for Transducer_Type for more information Ref. [HOCA-5, Chapter 4, page 50: Puretone, Speech and Noise signals] ## transCalStand2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="HearingInstrument_1_Condition" type="HearingInstrumentCondition_Type" default="NoCondition" minOccurs="0"> <xs:annotation> <xs:documentation>Indicates if a hearing instrument was worn by the patient during testing for condition 1 See annotations for HearingInstrumentCondtion_Type for more information ## condition1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="HearingInstrument_2_Condition" type="HearingInstrumentCondition_Type" default="NoCondition" minOccurs="0"> <xs:annotation> <xs:documentation>Indicates if a hearing instrument was worn by the patient during testing for condition 2 See annotations for HearingInstrumentCondtion_Type for more information ## condition2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="HearingInstrumentDescription" default="" minOccurs="0"> <xs:annotation> <xs:documentation>Generic text description of the hearing instrument(s) worn during the test ## instrDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusAuxiliary" type="AuxiliaryParameter_Type" default="NoAuxiliaryParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Word list type used for stimulus See AuxiliaryParameter_Type for more information ## auxParm1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingAuxiliary" type="AuxiliaryParameter_Type" default="NoAuxiliaryParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Word list type used for masking See AuxiliaryParameter_Type for more information ## auxParm2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="WordListName" minOccurs="0"> <xs:annotation> <xs:documentation>When testing a patient's speech discrimination a number of different sets of words can be used these are termed word lists (e.g. Maryland CNC word list or BKB Sentence list) ## wordListName ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="AuxiliaryParameterDescription" minOccurs="0"> <xs:annotation> <xs:documentation>Generic text description of the Auxiliary Parameters ## auxParmDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="SpeechThresholdType" type="SpeechThreshold_Type" default="NotUsed" minOccurs="0"> <xs:annotation> <xs:documentation>The type of speech threshold test See SpeechThreshold_Type for more information ## speechThresType ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusOnTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. An example is SISI - short increment sensitivity index testing where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. ## onTime1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingOnTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. ## onTime2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusOffTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is off between presentations (in seconds) in automatic tests. example is SISI - short increment sensitivity index testing where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. ## offTime1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingOffTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. ## offTime2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="3"/> <xs:minInclusive value="0.000"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusSiSiParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Defines the amount of decibel increase added to the carrier signal during SISI testing, commonly used values are 1,2 and 3 dB ## siSiParm1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingSiSiParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Masking is not commonly used for SiSi testing, ## ## siSiParm2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusWarbleModulation" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>The warble tone is a variation of the pure tone. The frequency of the basic tone is modulated in a desired pattern This is often used in free field Audiometry testing ## WarbleModFreq1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingWarbleModulation" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Warble Modulation is not commonly used. ## WarbleModFreq2 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusWarbleModulationSize" minOccurs="0"> <xs:annotation> <xs:documentation>The amplitude of the warble tone in percent of the steady tone. Measurement conditions typically used with DifferenceLimenFrequency testing. ## WarbleModSize1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingWarbleModulationSize" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Warble Modulation Size is not commonly used ## WarbleModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusFrequencyModulation" minOccurs="0"> <xs:annotation> <xs:documentation>The frequency of the basic tone is modulated by a lower frequency to produce a warble sound. Measurement conditions typically used with DifferenceLimenFrequency ## fmModSize1##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequencyModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Frequency Modulation is typically not used. ## fmModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusAmplitudeModulation" minOccurs="0"> <xs:annotation> <xs:documentation>The amplitude of the basic tone is modulated to produce a warble sound. Measurement conditions typically used with DifferenceLimenIntensity. ## AMModSize1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingAmplitudeModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Amplitude Modulation is typically not used ## AMModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusPulseModulation" minOccurs="0"> <xs:annotation> <xs:documentation>This is the frequency in Hz with which the signal is switched between the ears Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## ## pulseModFreq1 ## </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.0"/> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingPulseModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Pulse Modulation is typically not used ## pulseModFreq2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.0"/> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StimulusPulseCycle" minOccurs="0"> <xs:annotation> <xs:documentation>The Stimulus Pulse Cycle is the percentage of stimulus frequency where the signal is applied to the good ear. The rest of the pulse time is applied to the bad ear. This tells the audiometer how to cycle through that presentation when the stimulus present button is pressed. Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## pulseDutyCycle1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingPulseCycle" minOccurs="0"> <xs:annotation> <xs:documentation>In this case masking is understood to be the second measurement channel. This is the pulse time applied to the bad ear. Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## pulseDutyCycle2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> </xs:sequence> </xs:complexType> |
element AudioMetricMeasurementConditions_Type/StimulusSignalType
| diagram |  |
||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||
| type | restriction of Signal_Type | ||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusSignalType" default="NoSignalApplied"> <xs:annotation> <xs:documentation>Stimulus signal is the sound being presented to the patient, in the ear being tested, that you want them to respond to. (e.g. Pure Tone) @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalType1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="Signal_Type"/> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingSignalType
| diagram |  |
||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||
| type | Signal_Type | ||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingSignalType" type="Signal_Type" default="NoSignalApplied"> <xs:annotation> <xs:documentation>This is a sound used to stop the hearing in an ear that is not being tested from picking up the test signal. Often used when one ear is found to be significantly poorer than the other or for bone conduction testing. The non test ear picking up the test tone is called crossover. Masking is presented to the non test ear. An example of masking noise commonly used is narrowband noise (NBN) The enumerated value "NoSignalApplied" signals that masking has NOT been performed. If masking has been used then a value other then NoSignalApplied will and must be used. Ref. [HOCA-5, Chapter 9, page 124: Clinical Masking] ## SignalType2 ## @@ Translator/Converter RULE In the Audiogram format 100 and 200 it has been unclearly documented the exact method that must be used to note if masking is used or not. In some cases the signalType2 would be set correctly or in some cases it was not but yet freq2 or intentisty2 would be set (e.g. masking points would be saved). In other words there have been two ways to indicate that masking has been used. If a NOAH compatible program is to create an Audiogram using this XSD file and wishes to state that masking has not been used then it must set “NoSignalApplied” If a NOAH compatible program is reading format 100 or 200 translated to XML then the translator DLL must follow the below rule If (SignalType2 = NoSignal) AND There is at least (1 value for freq2 OR intensity2) for any of the available points then MaskingSignalType = “Unknown” @@</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusSignalOutput
| diagram |  |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| type | SignalOutput_Type | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusSignalOutput" type="SignalOutput_Type" default="NoSignalOutput"> <xs:annotation> <xs:documentation>This refers to the method used to deliver the sound the patient responds to. The ear and way the sound is delivered is specified but not the exact device used to deliver that sound (e.g. left air conduction not TDH39) See annotations for SignalOutput_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalOutput1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingSignalOutput
| diagram |  |
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| type | SignalOutput_Type | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingSignalOutput" type="SignalOutput_Type" default="NoSignalOutput"> <xs:annotation> <xs:documentation>This refers to the method used to deliver the masking sound to the patient. The ear and way the sound is delivered is specified but not the exact device used to deliver that sound. (e.g. left air conduction not TDH39) See annotations for SignalOutput_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## SignalOutput2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusdBWeighting
| diagram |  |
||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||
| type | dBweighting_Type | ||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusdBWeighting" type="dBweighting_Type" default="NodBWeighting"> <xs:annotation> <xs:documentation>The weighting used for the stimulus signal. See annotations for dBweighting_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## dBWeighting1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingdBWeighting
| diagram |  |
||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||
| type | dBweighting_Type | ||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingdBWeighting" type="dBweighting_Type" default="NodBWeighting"> <xs:annotation> <xs:documentation>The weighting used for the masking signal. See annotations for dBweighting_Type for more information @@ If the converter DLL for some reason find that this value is not correctly specified then it will set the value as unknown @@ ## dBWeighting2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusPresentationType
| diagram |  |
|||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||
| type | restriction of Presentation_Type | |||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusPresentationType" default="NoPresentationType" minOccurs="0"> <xs:annotation> <xs:documentation>Presentation Type for the Stimulus signal See annotations for Presentation_Type for more information ## presentType1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="Presentation_Type"/> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingPresentationType
| diagram |  |
|||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||
| type | Presentation_Type | |||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingPresentationType" type="Presentation_Type" default="NoPresentationType" minOccurs="0"> <xs:annotation> <xs:documentation>Presentation Type for the Masking signal See annotations for Presentation_Type for more information ## presentType 2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusTransducerType
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||
| type | Transducer_Type | |||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusTransducerType" type="Transducer_Type" default="NoTransducerType" minOccurs="0"> <xs:annotation> <xs:documentation>The device used to deliver sound to the test ear. See annotations for Transducer_Type for more information ## transType1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingTransducerType
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||
| type | Transducer_Type | |||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingTransducerType" type="Transducer_Type" default="NoTransducerType" minOccurs="0"> <xs:annotation> <xs:documentation>The device used to deliver sound to the non test ear. See annotations for Transducer_Type for more information ## transType2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/TransducerDescription
| diagram |  |
||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||
| type | restriction of xs:string | ||||||||
| properties |
|
||||||||
| facets |
|
||||||||
| annotation |
|
||||||||
| source | <xs:element name="TransducerDescription" default="" minOccurs="0"> <xs:annotation> <xs:documentation>Optional description of the Transducer ## transDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusTransducerCalibrationStandard
| diagram |  |
||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||
| type | TransducerCalibrationStandard_Type | ||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusTransducerCalibrationStandard" type="TransducerCalibrationStandard_Type" default="NoTransducerCalibrationStandard" minOccurs="0"> <xs:annotation> <xs:documentation>Standard used for the Stimulus Transducer Calibration See annotations for Transducer_Type for more information Ref. [HOCA-5, Chapter 4, page 50: Puretone, Speech and Noise signals] ## transCalStand1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingTransducerCalibrationStandard
| diagram | 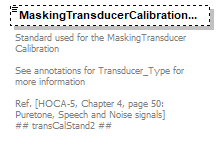 |
||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||
| type | TransducerCalibrationStandard_Type | ||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingTransducerCalibrationStandard" type="TransducerCalibrationStandard_Type" default="NoTransducerCalibrationStandard" minOccurs="0"> <xs:annotation> <xs:documentation>Standard used for the MaskingTransducer Calibration See annotations for Transducer_Type for more information Ref. [HOCA-5, Chapter 4, page 50: Puretone, Speech and Noise signals] ## transCalStand2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/HearingInstrument_1_Condition
| diagram |  |
|||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||
| type | HearingInstrumentCondition_Type | |||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||
| source | <xs:element name="HearingInstrument_1_Condition" type="HearingInstrumentCondition_Type" default="NoCondition" minOccurs="0"> <xs:annotation> <xs:documentation>Indicates if a hearing instrument was worn by the patient during testing for condition 1 See annotations for HearingInstrumentCondtion_Type for more information ## condition1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/HearingInstrument_2_Condition
| diagram | 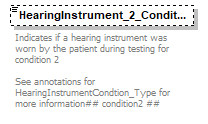 |
|||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||
| type | HearingInstrumentCondition_Type | |||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||
| source | <xs:element name="HearingInstrument_2_Condition" type="HearingInstrumentCondition_Type" default="NoCondition" minOccurs="0"> <xs:annotation> <xs:documentation>Indicates if a hearing instrument was worn by the patient during testing for condition 2 See annotations for HearingInstrumentCondtion_Type for more information ## condition2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/HearingInstrumentDescription
| diagram |  |
||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||
| type | restriction of xs:string | ||||||||
| properties |
|
||||||||
| facets |
|
||||||||
| annotation |
|
||||||||
| source | <xs:element name="HearingInstrumentDescription" default="" minOccurs="0"> <xs:annotation> <xs:documentation>Generic text description of the hearing instrument(s) worn during the test ## instrDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusAuxiliary
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | AuxiliaryParameter_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="StimulusAuxiliary" type="AuxiliaryParameter_Type" default="NoAuxiliaryParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Word list type used for stimulus See AuxiliaryParameter_Type for more information ## auxParm1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingAuxiliary
| diagram | 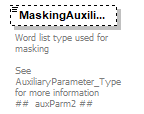 |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | AuxiliaryParameter_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="MaskingAuxiliary" type="AuxiliaryParameter_Type" default="NoAuxiliaryParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Word list type used for masking See AuxiliaryParameter_Type for more information ## auxParm2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/WordListName
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="WordListName" minOccurs="0"> <xs:annotation> <xs:documentation>When testing a patient's speech discrimination a number of different sets of words can be used these are termed word lists (e.g. Maryland CNC word list or BKB Sentence list) ## wordListName ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/AuxiliaryParameterDescription
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="AuxiliaryParameterDescription" minOccurs="0"> <xs:annotation> <xs:documentation>Generic text description of the Auxiliary Parameters ## auxParmDescr ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="16"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/SpeechThresholdType
| diagram |  |
|||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||
| type | SpeechThreshold_Type | |||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||
| source | <xs:element name="SpeechThresholdType" type="SpeechThreshold_Type" default="NotUsed" minOccurs="0"> <xs:annotation> <xs:documentation>The type of speech threshold test See SpeechThreshold_Type for more information ## speechThresType ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusOnTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusOnTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. An example is SISI - short increment sensitivity index testing where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. ## onTime1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingOnTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingOnTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. ## onTime2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusOffTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusOffTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is off between presentations (in seconds) in automatic tests. example is SISI - short increment sensitivity index testing where a continuous tone is presented 20dB above HTL and every 5 seconds the intensity of that tone increases by 1 dB and is held at that level for one- fifth of a second before reducing back to the original level. ## offTime1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.000"/> <xs:fractionDigits value="3"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingOffTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingOffTime" minOccurs="0"> <xs:annotation> <xs:documentation>Used to control how long a signal is presented, in seconds, when a button on the audiometer is pressed. ## offTime2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="3"/> <xs:minInclusive value="0.000"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusSiSiParameter
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusSiSiParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Defines the amount of decibel increase added to the carrier signal during SISI testing, commonly used values are 1,2 and 3 dB ## siSiParm1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingSiSiParameter
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingSiSiParameter" minOccurs="0"> <xs:annotation> <xs:documentation>Masking is not commonly used for SiSi testing, ## ## siSiParm2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusWarbleModulation
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusWarbleModulation" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>The warble tone is a variation of the pure tone. The frequency of the basic tone is modulated in a desired pattern This is often used in free field Audiometry testing ## WarbleModFreq1 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingWarbleModulation
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingWarbleModulation" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Warble Modulation is not commonly used. ## WarbleModFreq2 ##</xs:documentation> </xs:annotation> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusWarbleModulationSize
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusWarbleModulationSize" minOccurs="0"> <xs:annotation> <xs:documentation>The amplitude of the warble tone in percent of the steady tone. Measurement conditions typically used with DifferenceLimenFrequency testing. ## WarbleModSize1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingWarbleModulationSize
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingWarbleModulationSize" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Warble Modulation Size is not commonly used ## WarbleModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusFrequencyModulation
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusFrequencyModulation" minOccurs="0"> <xs:annotation> <xs:documentation>The frequency of the basic tone is modulated by a lower frequency to produce a warble sound. Measurement conditions typically used with DifferenceLimenFrequency ## fmModSize1##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingFrequencyModulation
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingFrequencyModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Frequency Modulation is typically not used. ## fmModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusAmplitudeModulation
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusAmplitudeModulation" minOccurs="0"> <xs:annotation> <xs:documentation>The amplitude of the basic tone is modulated to produce a warble sound. Measurement conditions typically used with DifferenceLimenIntensity. ## AMModSize1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingAmplitudeModulation
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingAmplitudeModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Amplitude Modulation is typically not used ## AMModSize2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusPulseModulation
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusPulseModulation" minOccurs="0"> <xs:annotation> <xs:documentation>This is the frequency in Hz with which the signal is switched between the ears Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## ## pulseModFreq1 ## </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.0"/> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingPulseModulation
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingPulseModulation" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Pulse Modulation is typically not used ## pulseModFreq2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.0"/> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/StimulusPulseCycle
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StimulusPulseCycle" minOccurs="0"> <xs:annotation> <xs:documentation>The Stimulus Pulse Cycle is the percentage of stimulus frequency where the signal is applied to the good ear. The rest of the pulse time is applied to the bad ear. This tells the audiometer how to cycle through that presentation when the stimulus present button is pressed. Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## pulseDutyCycle1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
element AudioMetricMeasurementConditions_Type/MaskingPulseCycle
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="MaskingPulseCycle" minOccurs="0"> <xs:annotation> <xs:documentation>In this case masking is understood to be the second measurement channel. This is the pulse time applied to the bad ear. Measurement conditions typically used with AlternateBinauralLoudnessBalanceConditions ## pulseDutyCycle2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
complexType DecayPoint_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel StartTime EndTime | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="DecayPoint_Type"> <xs:annotation> <xs:documentation>Data point for Decay sections ## TDecayPoint ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Intensity Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="StartTime"> <xs:annotation> <xs:documentation>Start time for a Decay presentation ## startTimeSec ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="EndTime"> <xs:annotation> <xs:documentation>Start and End time for a Decay presentation ## endTimeSec ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> </xs:sequence> </xs:complexType> |
element DecayPoint_Type/StimulusFrequency
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> |
element DecayPoint_Type/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DecayPoint_Type/MaskingFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> |
element DecayPoint_Type/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Intensity Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DecayPoint_Type/StartTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="StartTime"> <xs:annotation> <xs:documentation>Start time for a Decay presentation ## startTimeSec ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DecayPoint_Type/EndTime
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="EndTime"> <xs:annotation> <xs:documentation>Start and End time for a Decay presentation ## endTimeSec ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:fractionDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
complexType DifferenceLimenFrequencyPoint_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize DifferenceLimenFrequencyPointStatus | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="DifferenceLimenFrequencyPoint_Type"> <xs:annotation> <xs:documentation>Data point for Difference Limen Frequency (DLF) ## TDLFPoint ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>Modulation Size. The observed Difference Limen Threshold is saved as a percentage. This integer value represents the lowest detectable difference in frequency represented as described below: The Difference Limen (DL) will be saved for the variation in frequency in question in the variable modSize. In the DLF case the measurement becomes Frequency1A - Frequency1B Modulation Size = ___________________________________________ X 10,000 Frequency1A Intensity1A is defined as the measuring intensity and thus saved as intensity1. Intensity1B is the varied stimulus intensity. It can be increased or lowered. ## modSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:totalDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="DifferenceLimenFrequencyPointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of Point See PointStatus_Type enumeration for more details</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element DifferenceLimenFrequencyPoint_Type/StimulusFrequency
| diagram | 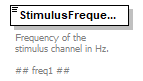 |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> |
element DifferenceLimenFrequencyPoint_Type/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenFrequencyPoint_Type/MaskingFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> |
element DifferenceLimenFrequencyPoint_Type/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenFrequencyPoint_Type/ModulationSize
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>Modulation Size. The observed Difference Limen Threshold is saved as a percentage. This integer value represents the lowest detectable difference in frequency represented as described below: The Difference Limen (DL) will be saved for the variation in frequency in question in the variable modSize. In the DLF case the measurement becomes Frequency1A - Frequency1B Modulation Size = ___________________________________________ X 10,000 Frequency1A Intensity1A is defined as the measuring intensity and thus saved as intensity1. Intensity1B is the varied stimulus intensity. It can be increased or lowered. ## modSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:minInclusive value="0.00"/> <xs:totalDigits value="2"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenFrequencyPoint_Type/DifferenceLimenFrequencyPointStatus
| diagram |  |
|||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||
| type | PointStatus_Type | |||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||
| source | <xs:element name="DifferenceLimenFrequencyPointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of Point See PointStatus_Type enumeration for more details</xs:documentation> </xs:annotation> </xs:element> |
complexType DifferenceLimenIntensityPoint_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize DifferenceLimenIntensityPointStatus | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="DifferenceLimenIntensityPoint_Type"> <xs:annotation> <xs:documentation>Data point for Difference Limen Intensity (DLI) thresholds The difference limen (DL) will be saved for the frequency in question in the variable modSize. ## TDLIPoint ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz ## freq2##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>Modulation Size. The observed Difference Limen Threshold measured in dB. This value represents the lowest detectable difference in Sound Pressure Level. ## modSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> <xs:minInclusive value="0.0"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="DifferenceLimenIntensityPointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of the point See PointStatus_Type annotations for more details</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element DifferenceLimenIntensityPoint_Type/StimulusFrequency
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> |
element DifferenceLimenIntensityPoint_Type/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenIntensityPoint_Type/MaskingFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz ## freq2##</xs:documentation> </xs:annotation> </xs:element> |
element DifferenceLimenIntensityPoint_Type/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenIntensityPoint_Type/ModulationSize
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>Modulation Size. The observed Difference Limen Threshold measured in dB. This value represents the lowest detectable difference in Sound Pressure Level. ## modSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> <xs:minInclusive value="0.0"/> </xs:restriction> </xs:simpleType> </xs:element> |
element DifferenceLimenIntensityPoint_Type/DifferenceLimenIntensityPointStatus
| diagram |  |
|||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||
| type | PointStatus_Type | |||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||
| source | <xs:element name="DifferenceLimenIntensityPointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of the point See PointStatus_Type annotations for more details</xs:documentation> </xs:annotation> </xs:element> |
complexType FrequenciesUsedForToneAverage_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | LeftEar1 LeftEar2 RightEar1 RightEar2 | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="FrequenciesUsedForToneAverage_Type"> <xs:annotation> <xs:documentation>## TToneAvgCalcValues; ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="LeftEar1" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for LeftEar1 ## TToneAvg ## </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="ToneAverage_Type"/> </xs:simpleType> </xs:element> <xs:element name="LeftEar2" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for LeftEar2 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> <xs:element name="RightEar1" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for RightEar1 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> <xs:element name="RightEar2" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for RightEar2 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element FrequenciesUsedForToneAverage_Type/LeftEar1
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of ToneAverage_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="LeftEar1" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for LeftEar1 ## TToneAvg ## </xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="ToneAverage_Type"/> </xs:simpleType> </xs:element> |
element FrequenciesUsedForToneAverage_Type/LeftEar2
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | ToneAverage_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="LeftEar2" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for LeftEar2 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> |
element FrequenciesUsedForToneAverage_Type/RightEar1
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | ToneAverage_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="RightEar1" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for RightEar1 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> |
element FrequenciesUsedForToneAverage_Type/RightEar2
| diagram |  |
|||||||||||||||||||||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | ToneAverage_Type | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:element name="RightEar2" type="ToneAverage_Type" minOccurs="0" maxOccurs="13"> <xs:annotation> <xs:documentation>Frequencies used to calculate the average for RightEar2 ## TToneAvg ## </xs:documentation> </xs:annotation> </xs:element> |
complexType MeasurementNotes_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | AudiometerMakeModel AudiometerSerialNumber AudiometerLastCalibration TestMethod TestReliability | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="MeasurementNotes_Type"> <xs:annotation> <xs:documentation>The Measurement Notes structure is designed to hold the notes from an Audiological Measurement. The information herein could be useful to other entities as the information affects the test and its results. ## TMeasurementNotes ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="AudiometerMakeModel" minOccurs="0"> <xs:annotation> <xs:documentation>The Manufacturer Make Model of the equipment used. ## makeModel ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="AudiometerSerialNumber" minOccurs="0"> <xs:annotation> <xs:documentation>The Manufacturer Serial Number of the equipment used. ## serialNo ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="AudiometerLastCalibration" type="xs:dateTime" minOccurs="0"> <xs:annotation> <xs:documentation>Date of Last Calibration of the equipment used. ## dateOfLastCalibration ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="TestMethod" minOccurs="0"> <xs:annotation> <xs:documentation>It is possible to carry out Audiological tests according to a number of different protocols. This field allows the actual method of testing to be described. For example, Visual reinforcement Audiometry is used to achieve a Pure Tone Audiogram from small children and the audiologist would comment that testing was performed using this method. ## testMethod ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="TestReliability" minOccurs="0"> <xs:annotation> <xs:documentation>Patients are required to respond consistently at the same level during pure tone audiometry in order to find their HTL accurately. For some patients this is not possible and an accurate HTL cannot be established because the patient responds at varying levels during the testing claiming them to be their HTL. The audiologist would generally remark that the responses were not accurate by writing a comment in the reliability field ## testReliability ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> </xs:sequence> </xs:complexType> |
element MeasurementNotes_Type/AudiometerMakeModel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="AudiometerMakeModel" minOccurs="0"> <xs:annotation> <xs:documentation>The Manufacturer Make Model of the equipment used. ## makeModel ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> |
element MeasurementNotes_Type/AudiometerSerialNumber
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="AudiometerSerialNumber" minOccurs="0"> <xs:annotation> <xs:documentation>The Manufacturer Serial Number of the equipment used. ## serialNo ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> |
element MeasurementNotes_Type/AudiometerLastCalibration
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:dateTime | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="AudiometerLastCalibration" type="xs:dateTime" minOccurs="0"> <xs:annotation> <xs:documentation>Date of Last Calibration of the equipment used. ## dateOfLastCalibration ##</xs:documentation> </xs:annotation> </xs:element> |
element MeasurementNotes_Type/TestMethod
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="TestMethod" minOccurs="0"> <xs:annotation> <xs:documentation>It is possible to carry out Audiological tests according to a number of different protocols. This field allows the actual method of testing to be described. For example, Visual reinforcement Audiometry is used to achieve a Pure Tone Audiogram from small children and the audiologist would comment that testing was performed using this method. ## testMethod ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> |
element MeasurementNotes_Type/TestReliability
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:string | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="TestReliability" minOccurs="0"> <xs:annotation> <xs:documentation>Patients are required to respond consistently at the same level during pure tone audiometry in order to find their HTL accurately. For some patients this is not possible and an accurate HTL cannot be established because the patient responds at varying levels during the testing claiming them to be their HTL. The audiologist would generally remark that the responses were not accurate by writing a comment in the reliability field ## testReliability ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:string"> <xs:maxLength value="41"/> </xs:restriction> </xs:simpleType> </xs:element> |
complexType ShortIncrementSensitivityIndexPoint
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel ModulationSize NumberOfAnswers NumberOfIncrements | ||
| used by |
|
||
| annotation |
|
||
| source | <xs:complexType name="ShortIncrementSensitivityIndexPoint"> <xs:annotation> <xs:documentation>Data point for Short Increment Sensitivity Index (SISI) Audiogram ## TSiSiPoint ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>The observed SiSi Increment size measured in dB. This value represents the lowest detectable difference in Sound Pressure Level ## ModSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="NumberOfAnswers" type="xs:integer"> <xs:annotation> <xs:documentation>Number of positive responses given by the patient corresponding to the saved increment size. ## TSiSiIncrements ##</xs:documentation> </xs:annotation> </xs:element> <xs:element name="NumberOfIncrements" type="xs:integer"> <xs:annotation> <xs:documentation>The total number of presentations given with the corresponding increment size ## TSiSiIncrements ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element ShortIncrementSensitivityIndexPoint/StimulusFrequency
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz. ## freq1 ##</xs:documentation> </xs:annotation> </xs:element> |
element ShortIncrementSensitivityIndexPoint/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element ShortIncrementSensitivityIndexPoint/MaskingFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency of the masking channel in Hz. ## freq2##</xs:documentation> </xs:annotation> </xs:element> |
element ShortIncrementSensitivityIndexPoint/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element ShortIncrementSensitivityIndexPoint/ModulationSize
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="ModulationSize"> <xs:annotation> <xs:documentation>The observed SiSi Increment size measured in dB. This value represents the lowest detectable difference in Sound Pressure Level ## ModSize ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element ShortIncrementSensitivityIndexPoint/NumberOfAnswers
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="NumberOfAnswers" type="xs:integer"> <xs:annotation> <xs:documentation>Number of positive responses given by the patient corresponding to the saved increment size. ## TSiSiIncrements ##</xs:documentation> </xs:annotation> </xs:element> |
element ShortIncrementSensitivityIndexPoint/NumberOfIncrements
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="NumberOfIncrements" type="xs:integer"> <xs:annotation> <xs:documentation>The total number of presentations given with the corresponding increment size ## TSiSiIncrements ##</xs:documentation> </xs:annotation> </xs:element> |
complexType SpeechScorePoint_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusLevel MaskingLevel ScorePercent NumberOfWords | ||
| used by | |||
| annotation |
|
||
| source | <xs:complexType name="SpeechScorePoint_Type"> <xs:annotation> <xs:documentation>Data point for Speech Scores, used by all speech audiograms ## TSpeechPoint ##</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="ScorePercent"> <xs:annotation> <xs:documentation>The number of correct repeated phonemes (words, syllables…) in percent ## scorePct ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="NumberOfWords" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>The number of correctly repeated phonemes (words, syllables…) ## words ##</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element SpeechScorePoint_Type/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element SpeechScorePoint_Type/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element SpeechScorePoint_Type/ScorePercent
| diagram |  |
|||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||
| type | restriction of xs:decimal | |||||||||
| properties |
|
|||||||||
| facets |
|
|||||||||
| annotation |
|
|||||||||
| source | <xs:element name="ScorePercent"> <xs:annotation> <xs:documentation>The number of correct repeated phonemes (words, syllables…) in percent ## scorePct ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="2"/> <xs:minInclusive value="0.00"/> </xs:restriction> </xs:simpleType> </xs:element> |
element SpeechScorePoint_Type/NumberOfWords
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="NumberOfWords" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>The number of correctly repeated phonemes (words, syllables…) ## words ##</xs:documentation> </xs:annotation> </xs:element> |
complexType TonePoints_Type
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| children | StimulusFrequency StimulusLevel MaskingFrequency MaskingLevel TonePointStatus | ||
| used by | |||
| annotation |
|
||
| source | <xs:complexType name="TonePoints_Type"> <xs:annotation> <xs:documentation>Data point used to store curve points of tone audiograms ## TTonePoint ## @@ HIMSA has noticed that some modules saving in format 100 or 200 have setup many AudMeasurementConditions for curve but then never entered any actual points. If the TonePoints collection is empty then the curve must not be converted to XML, doing so allows for a much smaller XML file @@</xs:documentation> </xs:annotation> <xs:sequence> <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz ## freq1 ## @@ HIMSA has found that some modules saving in format 100 or 200 have improperly used the value of 0 (zero) to denote an empty value. This use causes a very inefficient creation of XML files. If all the StimulusFrequency elements contain the value of 0 for a given curve then do not convert the StimulusFrequency and corresponding StimulusLevel elements as they do not represent useful data. The same rule applies to MaskingFrequency and MaskingLevel @@ </xs:documentation> </xs:annotation> </xs:element> <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency for masking channel If masking is to be recorded it is then necessary to save values for both MaskingFrequency and MaskingLevel. The XSD was not able to be setup to enforce this rule due to legacy (format 200) design. ## freq2 ## @@ HIMSA has found that some modules saving in format 100 or 200 have improperly used the value of 0 (zero) to denote an empty value. This use causes a very inefficient creation of XML files. If all the StimulusFrequency elements contain the value of 0 for a given curve then do not convert the StimulusFrequency and corresponding StimulusLevel elements as they do not represent useful data. The same rule applies to MaskingFrequency and MaskingLevel @@ </xs:documentation> </xs:annotation> </xs:element> <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB If masking is to be recorded it is then necessary to save values for both MaskingFrequency and MaskingLevel. The XSD was not able to be setup to enforce this rule due to legacy (format 200) design. ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> <xs:element name="TonePointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of the point See PointStatus_Type annotation notes for more information</xs:documentation> </xs:annotation> </xs:element> </xs:sequence> </xs:complexType> |
element TonePoints_Type/StimulusFrequency
| diagram |  |
||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||
| type | xs:integer | ||
| properties |
|
||
| annotation |
|
||
| source | <xs:element name="StimulusFrequency" type="xs:integer"> <xs:annotation> <xs:documentation>Frequency of the stimulus channel in Hz ## freq1 ## @@ HIMSA has found that some modules saving in format 100 or 200 have improperly used the value of 0 (zero) to denote an empty value. This use causes a very inefficient creation of XML files. If all the StimulusFrequency elements contain the value of 0 for a given curve then do not convert the StimulusFrequency and corresponding StimulusLevel elements as they do not represent useful data. The same rule applies to MaskingFrequency and MaskingLevel @@ </xs:documentation> </xs:annotation> </xs:element> |
element TonePoints_Type/StimulusLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="StimulusLevel"> <xs:annotation> <xs:documentation>Stimulus Level of the stimulus channel in dB ## intensity1 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element TonePoints_Type/MaskingFrequency
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | xs:integer | ||||||
| properties |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingFrequency" type="xs:integer" minOccurs="0"> <xs:annotation> <xs:documentation>Frequency for masking channel If masking is to be recorded it is then necessary to save values for both MaskingFrequency and MaskingLevel. The XSD was not able to be setup to enforce this rule due to legacy (format 200) design. ## freq2 ## @@ HIMSA has found that some modules saving in format 100 or 200 have improperly used the value of 0 (zero) to denote an empty value. This use causes a very inefficient creation of XML files. If all the StimulusFrequency elements contain the value of 0 for a given curve then do not convert the StimulusFrequency and corresponding StimulusLevel elements as they do not represent useful data. The same rule applies to MaskingFrequency and MaskingLevel @@ </xs:documentation> </xs:annotation> </xs:element> |
element TonePoints_Type/MaskingLevel
| diagram |  |
||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||
| type | restriction of xs:decimal | ||||||
| properties |
|
||||||
| facets |
|
||||||
| annotation |
|
||||||
| source | <xs:element name="MaskingLevel" minOccurs="0"> <xs:annotation> <xs:documentation>Masking Level of the masking channel in dB If masking is to be recorded it is then necessary to save values for both MaskingFrequency and MaskingLevel. The XSD was not able to be setup to enforce this rule due to legacy (format 200) design. ## intensity2 ##</xs:documentation> </xs:annotation> <xs:simpleType> <xs:restriction base="xs:decimal"> <xs:fractionDigits value="1"/> </xs:restriction> </xs:simpleType> </xs:element> |
element TonePoints_Type/TonePointStatus
| diagram |  |
|||||||||||||||||||||||||||||||||
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||
| type | PointStatus_Type | |||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||
| source | <xs:element name="TonePointStatus" type="PointStatus_Type"> <xs:annotation> <xs:documentation>Status of the point See PointStatus_Type annotation notes for more information</xs:documentation> </xs:annotation> </xs:element> |
simpleType AuxiliaryParameter_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="AuxiliaryParameter_Type"> <xs:annotation> <xs:documentation>Typically used with speech testing Types of word list used to carry out speech testing. Some are used for speech discrimination testing but others are there for more specific tests of speech understanding in noise for example. This does not define the actual word list used by name just by the type ## TAUXParm ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoAuxiliaryParameter"/> <xs:enumeration value="MonoSyllabicWords"/> <xs:enumeration value="MultiSyllabicWords"/> <xs:enumeration value="DichoticWords"/> <xs:enumeration value="Freiburger"/> <xs:enumeration value="Reim"/> <xs:enumeration value="Numerals"/> <xs:enumeration value="SpondaicWords"/> <xs:enumeration value="ConversationalSpeech"/> <xs:enumeration value="PhoneticallyBalanced"/> <xs:enumeration value="SentenceMaterial"/> <xs:enumeration value="BodyParts"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType dBweighting_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | ||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||
| used by |
|
||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||
| source | <xs:simpleType name="dBweighting_Type"> <xs:annotation> <xs:documentation>The decibel scale is used to measure the level of sound presented to the ears relative to a reference point. The decibel scales express a ratio between two numbers these are converted to a logarithmic scale. As this is a ratio we must have a reference level - you cannot say the sound is 10 times bigger if you do not state what it is bigger than. This reference point varies between different dB scales. For example dBSPL uses audiometric zero as it's reference point which is measured in Pascals and is the minimum pressure required to cause the sensation of hearing in the mid frequency region, (0,0002Pa). There are a number of different scales to use when measuring hearing thresholds on all of which use decibels with different reference points. The stimulus dB weighting is used to determine how much correction is required so that the audiometer dials read accurately for the chosen measurement scale. This will vary between tests e.g. dBSPL and dBHL measurements will have different dB weightings. ABS / Absolute Value of a measurement without any corrections CSL / Comfortable Speech Level. According to ISO standard. ## TdBWeighting ## ## Enumerated Value HTL has been changed to HL ## </xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NodBWeighting"/> <xs:enumeration value="HL"/> <xs:enumeration value="SPL"/> <xs:enumeration value="ABS"/> <xs:enumeration value="CSL"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType HearingInstrumentCondition_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||
| source | <xs:simpleType name="HearingInstrumentCondition_Type"> <xs:annotation> <xs:documentation>The Hearing Instrument Condition Type indicates whether the patient wore a Hearing Instrument during the measurement. The NOAH 3.0 Audiogram Module specification allows a user to specify both an Aided1 and an Aided2 condition to differentiate between tests with two different types of Hearing Instruments. This scenario may mean that the user enters data in an Aided2 field without corresponding information on the Aided1 test condition. ## THICondition ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoCondition"/> <xs:enumeration value="UnAided"/> <xs:enumeration value="Aided1"/> <xs:enumeration value="Aided2"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType PointStatus_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="PointStatus_Type"> <xs:annotation> <xs:documentation>Notes for Enumerated Values: + Unknown / The parameter is defined, but to the value Unknown + Normal / Valid threshold point. Used for valid curve points at the threshold: For this threshold point, the patient could hear and respond to the presented stimulus 50 pct. of the time. (from the definition of a threshold). + AlwaysResponse / Patient might hear better than this. Used for valid curve points probably above the threshold:, The patient could hear and respond to the presented stimulus all of the time. + NoResponse / Patient did not respond. The stimulus was at the highest output level of the measurement device, but the patient did not respond. In pure tone graph, a point is plotted at the dB level corresponding to the highest output level of the measuring device. + NotMeasurable / Presented stimulus to patient but without a result. It was not possible to measure threshold consistently or reliably. A point is plotted at the dB level that best represents the test results + DidNotTest / The stimulus was not presented to subject. Reasons: Per instruction by physician or because the test was judged to be unnecessary. No point was plotted. + CouldNotTest / Unable to present stimulus.Reasons: Subject's physical or behavioral limitations. No point was plotted. ## NoStatus enumerated value has been changed to Normal ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="Normal"/> <xs:enumeration value="AlwaysResponse"/> <xs:enumeration value="NoResponse"/> <xs:enumeration value="NotMeasurable"/> <xs:enumeration value="DidNotTest"/> <xs:enumeration value="CouldNotTest"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType Presentation_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="Presentation_Type"> <xs:annotation> <xs:documentation>Presentation is done in a number of different ways. In some tests the stimulus is always on (i.e. using the continuous presentation type)- (e.g. Tone Decay presents a continuous pure tone signal.) Some of the stimulus types in this section are specific to diagnostic tests such as: + SISI ./ Short Increment Sensitivity Index + Alternating / usually used with ABLB testing (Alternate Binaural Loudness balance) + Amplitude Modulated / used in Bekesey Audiometry (automatic) + StepWiseFrequencyModulated / often called ‘warble tones’ can be used in free field testing + Impulse / Random pulses + Pulsed Presentation / Used in Bekesey Audiometry (automatic) and can be used as part of pure tone audiometry to make it easier for patients to distinguish stimulus sound ## TPresentType ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoPresentationType"/> <xs:enumeration value="Continuous"/> <xs:enumeration value="PulsedPresentation"/> <xs:enumeration value="Alternating"/> <xs:enumeration value="AmplitudeModulated"/> <xs:enumeration value="StepwiseFrequencyModulated"/> <xs:enumeration value="Impulse"/> <xs:enumeration value="SiSiSignal"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType Signal_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | ||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||
| used by |
|
||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="Signal_Type"> <xs:annotation> <xs:documentation>AuxiliarySignal / Stimulus from Compact Disc or Audio Tape Microphone / Live voice from microphone ## TSignalType ## ##NoSignal now is NoSignalApplied ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoSignalApplied"/> <xs:enumeration value="PureTone"/> <xs:enumeration value="Warble"/> <xs:enumeration value="NarrowBandNoise"/> <xs:enumeration value="SpeechNoise"/> <xs:enumeration value="WhiteNoise"/> <xs:enumeration value="PinkNoise"/> <xs:enumeration value="AuxiliarySignal"/> <xs:enumeration value="Microphone"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType SignalOutput_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | ||||||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| used by |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="SignalOutput_Type"> <xs:annotation> <xs:documentation>The Signal Output Type is of extra importance. It defines the means of presenting sound to the patient: + Air Conductor / headphones + Bone conductor / vibrator placed on the mastoid (HOCA-5 page 10) + Free Field / Loudspeakers in a special test room + Insert Phone / small foam tips used to deliver air conduction test It also defines which side (i.e. the persons left or right ear) is stimulated. ## TSignalOutput ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoSignalOutput"/> <xs:enumeration value="AirConductorLeft"/> <xs:enumeration value="AirConductorRight"/> <xs:enumeration value="AirConductorBinaural"/> <xs:enumeration value="BoneConductorLeft"/> <xs:enumeration value="BoneConductorRight"/> <xs:enumeration value="BoneConductorBinaural"/> <xs:enumeration value="FreeFieldLeft"/> <xs:enumeration value="FreeFieldRight"/> <xs:enumeration value="FreeFieldBinaural"/> <xs:enumeration value="InsertPhoneLeft"/> <xs:enumeration value="InsertPhoneRight"/> <xs:enumeration value="InsertPhoneBinaural"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType SpeechThreshold_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||
| source | <xs:simpleType name="SpeechThreshold_Type"> <xs:annotation> <xs:documentation> This enumerated type is used for speech testing to determine if the test used is of type SAT, SDT or SRT. Speech is used as the stimulus in these tests. +SRT - Speech recognition threshold test / The level at which 50% correct score is obtained when patients are asked to repeat a spondaic word list. - Spondaic words are 2 syllable words with equal stress on each syllable.( e.g. Birthday) +SDT - Speech Detection threshold test / A single word is presented repeatedly and the intensity is increased in 5dB steps and decreased in 10dB steps (like pure tone audiometry) until the point where the patient indicates they can detect, but not repeat the speech heard. Threshold (again like pure tone audiometry) is taken as the level where the patient responds 2 out of 3 or 2 out of 4 times. +SAT Speech Awareness Threshold Test / Same Description as of SDT ## TSpeechThresholdType ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NotUsed"/> <xs:enumeration value="SRT"/> <xs:enumeration value="SDT"/> <xs:enumeration value="SAT"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType ToneAverage_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="ToneAverage_Type"> <xs:annotation> <xs:documentation> Frequency Values used to calculate the average In the event that a XML file is saved into NOAH (e.g. a new NOAH module is saving in version 500) it is technically possible for a frequency to be listed more than once as this would validate fine. In the event that a program is reading the data then the additional entry will effectively need to be ignored ##TToneAvg##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="125"/> <xs:enumeration value="250"/> <xs:enumeration value="500"/> <xs:enumeration value="750"/> <xs:enumeration value="1000"/> <xs:enumeration value="1500"/> <xs:enumeration value="2000"/> <xs:enumeration value="3000"/> <xs:enumeration value="4000"/> <xs:enumeration value="6000"/> <xs:enumeration value="8000"/> <xs:enumeration value="12000"/> <xs:enumeration value="16000"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType Transducer_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | |||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | |||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
|||||||||||||||||||||||||||||||||||||||||||||
| used by |
|
|||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
|||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
|||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="Transducer_Type"> <xs:annotation> <xs:documentation>The device used to deliver sound (e.g. type of headphone TDH39) A simple explanation for each type of device is provided below: + TDH39 / Supra aural headphones for air conduction tests + HDA200 / Supra aural headphones often used for extended high frequency air conduction testing + EarTone 3A / Insert earphones + DT48 / Supra aural headphones for air conduction tests + TDH49 / Supra aural headphones for air conduction tests + B71 / Bone Conductor + B72 / Bone conductor + Beoton / specific set of headphones used with Beoton audiometers only + Holmberg / Supra aural headphones for air conduction tests usually used in noisier environments ## TTransType ##</xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoTransducerType"/> <xs:enumeration value="TDH39"/> <xs:enumeration value="HDA200"/> <xs:enumeration value="EARTONE3A"/> <xs:enumeration value="DT48"/> <xs:enumeration value="TDH49"/> <xs:enumeration value="B71"/> <xs:enumeration value="B72"/> <xs:enumeration value="Beoton"/> <xs:enumeration value="Holmberg"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
simpleType TransducerCalibrationStandard_Type
| namespace | http://www.himsa.com/Measurement/Audiogram | ||||||||||||||||||||||||||||||||||||||||||||||||
| type | restriction of xs:NMTOKEN | ||||||||||||||||||||||||||||||||||||||||||||||||
| properties |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| used by |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| facets |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| annotation |
|
||||||||||||||||||||||||||||||||||||||||||||||||
| source | <xs:simpleType name="TransducerCalibrationStandard_Type"> <xs:annotation> <xs:documentation>Different ISO and ANSI standards available for transducer calibration. The calibration standards are available for a number of typical transducers ## TTransCalStand ## </xs:documentation> </xs:annotation> <xs:restriction base="xs:NMTOKEN"> <xs:enumeration value="Unknown"/> <xs:enumeration value="NoTransducerCalibrationStandard"/> <xs:enumeration value="ISO389"/> <xs:enumeration value="ISO389_FFEQ"/> <xs:enumeration value="ISO7566"/> <xs:enumeration value="ISO7566_FFEQ"/> <xs:enumeration value="ISO8798"/> <xs:enumeration value="ISO8798_FFEQ"/> <xs:enumeration value="ISO226"/> <xs:enumeration value="ISO226_FFEQ"/> <xs:enumeration value="ANSIS36"/> <xs:enumeration value="ANSIS36_FFEQ"/> <xs:enumeration value="User1"/> <xs:enumeration value="User2"/> <xs:enumeration value="User3"/> </xs:restriction> </xs:simpleType> |
XML Schema documentation generated by XMLSpy Schema Editor http://www.altova.com/xmlspy